Someone report this bug. The reporter doesn’t seem to see this issue in his distro (Fedora 34) anymore. But I still do in my Fedora 34 happening every time whenever power on the OS. Very reproducable. Since this bug report lacked important logs, I wanted to pitch in and give them what might be helpful in solving this issue.
So after reading their discussion, I installed different debugging packages using this command: sudo dnf debuginfo-install gdm glic2
Read the journalctl output to get the PID so that I can use it later in coredumpctl command.
pranav@fedora ~> journalctl -b | rg -B3 -A5 -i 'glib'
Sep 15 09:37:53 fedora ibus-daemon[1338]: GChildWatchSource: Exit status of a child process was requested but ECHILD was received by waitpid(). See the documentation of g_child_watch_source_new() for possible causes.
Sep 15 09:37:53 fedora gdm-launch-environment][883]: pam_unix(gdm-launch-environment:session): session closed for user gdm
Sep 15 09:37:53 fedora audit[883]: USER_END pid=883 uid=0 auid=4294967295 ses=4294967295 subj=system_u:system_r:xdm_t:s0-s0:c0.c1023 msg='op=PAM:session_close grantors=pam_keyinit,pam_keyinit,pam_limits,pam_systemd,pam_unix,pam_umask acct="gdm" exe="/usr/libexec/gdm-session-worker" hostname=fedora addr=? terminal=/dev/tty1 res=success'
Sep 15 09:37:53 fedora audit[883]: CRED_DISP pid=883 uid=0 auid=4294967295 ses=4294967295 subj=system_u:system_r:xdm_t:s0-s0:c0.c1023 msg='op=PAM:setcred grantors=pam_permit acct="gdm" exe="/usr/libexec/gdm-session-worker" hostname=fedora addr=? terminal=/dev/tty1 res=success'
Sep 15 09:37:53 fedora gdm-launch-environment][883]: GLib-GObject: g_object_unref: assertion 'G_IS_OBJECT (object)' failed
Sep 15 09:37:53 fedora gsd-color[1825]: failed to connect to device: Failed to connect to missing device /org/freedesktop/ColorManager/devices/xrandr_AU_Optronics_gdm_42
Sep 15 09:37:53 fedora systemd-logind[827]: Session c1 logged out. Waiting for processes to exit.
Since it said, gdm-launch-environment [883], I did this:
pranav@fedora ~> coredumpctl gdb 883
No match found.
At this point, I think I have annoyed Gnome Triage named Andre because I was polluting this GitHub issue with back-and-forth questions about, “why I’m not getting the logs, how to get the logs”. He recommended me to come here and ask. Here I am. The last thing he said was, "Your corefiles are missing above. So there’s no data to look at. "
Note: no need to use sudo when running coredumpctl.
Huh, that’s strange.
Assuming you have made no custom changes to your systemd-coredump configuration under /etc/systemd/coredump.conf or /etc/systemd/system.conf.d, then my only guess is your core dumps were deleted because systemd-coredump is configured to keep 15% of your disk free by default, so core dumps will be deleted if you have less than 15% disk space remaining. Maybe your disk is pretty full?
If not, then have you made any configuration changes in /etc/systemd/coredump.conf or /etc/systemd/system.conf.d?
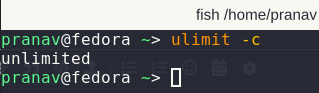
Also, please verify that you have not made any custom changes to your core limit: ulimit -c should print unlimited.
please verify that you have not made any custom changes to your core limit
As you can see there is no custom limit. But I do a limit in journalctl logs.
Is there a similar verfiy command to be sure whether I have limit in journalctl logs or not?
Are coredump or core limit related with journalctl? If not, than we can totally ignore question 1.
journalctl --verify gives me a lot of red lines which start with a warnings, “File corruption detected at …” as you can see here. Is is normal? or does it need some fixes too?!
I’m not sure, it could be. By default, systemd-coredump stores short backtraces in the journal, so if your journal is corrupt I imagine those might not be available. But core dumps are no longer stored in the journal by default, nowadays they are stored externally (again assuming you have made no configuration changes yourself).
Anyway, fixing your journal does m
No, that’s definitely not normal. I would trash your journal (not sure how to do that) and start over from scratch. I would also consider that a hardware problem is very likely. My guess is bad RAM. I had the same problem in the past, and it turned out that my RAM was broken, flipping bits.
" journalctl --verify gives me a lot of red lines which start with warnings, “File corruption detected at …” after reading a lot of forums Q&A, journalctl getting corrupted is pretty common. The only solution is to deleted those corrupted coredumps which has missing corefiles and also deleted journalctl files which has been corrupted.
When you said, “My guess is bad RAM.”. I was quite shocked. Thoughts like, “So RAM can do all other activities fine but it journalctl, it must be a because of bad RAM?!” came in my mind.
Anyway, Systemd has open issue relating to journalctl doing so. Apparently, this is a famous issue. When u type journalctl --verify chances are, there are file corruption in your too. Unless you have ECC memory.
Do you know how to delete a coredump and journctl log of a particular day (like Sunday) or a particular name?
Hm, you’re right. I actually do have ECC memory now, but I see the same errors as you when I type journalctl --verify. What I was remembering was different: when I had bad RAM, the journal metadata got corrupted and journalctl could no longer show any log messages at all. That was a different level of badness altogether.
I think you would have to manually clear them from the journal. It’s not worth trying to do this. Missing older core dumps is perfectly normal since systemd cleans them periodically. What’s important here is that it shows you do have core dumps saved for those three recent ibus crashes, so it looks like your coredumps are now being saved properly.
If you see log messages when you run journalctl, then I wouldn’t worry about it.
Instead of installing 100’s debugging packages one had to install in order to get stacktrace from GDB, I have now decided to use a third-party tool named Valgrind. I hope it’s not a bad idea. But I can’t seem to why it’s not working the way I’m doing it here:
pranav@fedora ~> sudo valgrind gnome-shell
[sudo] password for pranav:
==5588==
==5588== Warning: Can't execute setuid/setgid/setcap executable: /usr/bin/gnome-shell
==5588== Possible workaround: remove --trace-children=yes, if in effect
==5588==
valgrind: /usr/bin/gnome-shell: Permission denied
pranav@fedora ~> sudo valgrind --trace-children=yes gnome-shell
==5777==
==5777== Warning: Can't execute setuid/setgid/setcap executable: /usr/bin/gnome-shell
==5777== Possible workaround: remove --trace-children=yes, if in effect
==5777==
valgrind: /usr/bin/gnome-shell: Permission denied