I would very much like to point out that the core of this proposal is to side-step the entire “generate a tarball” approach.
Yes, having a CI pipeline running distcheck is good and fine, and we can automate it; the main issue is taking the tarball and uploading it somewhere: we cannot add the SSH keys to the GNOME FTP share to the CI runners.
One option is to have the CI pipeline store the release archive as an artifact for, say, 24 hours; when the pipeline ends, we could use something like:
curl -X POST \
-F project=${CI_PROJECT_NAME} \
-F branch=${CI_COMMIT_BRANCH} \
-F archive=${TARBALL_FILE} \
download.gnome.org
And have a simple service on download.gnome.org answering to that request (if it’s coming from an authorised project on gitlab.gnome.org, of course) that will download the tarball from the CI artifacts of the given branch. Both GTK and libadwaita use a similar approach to download the API references generated on various branches, in order to publish them.
This approach would also eliminate the need to hand out SSH access to maintainers in order to upload archives to master.gnome.org.
From a maintainer’s perspective, including the release team’s one, the tarball is just a byproduct; it’s just not important.
The less convoluted approach is to have people download the release artifact associated to a tag; for instance, GLib’s 2.73.2 release:
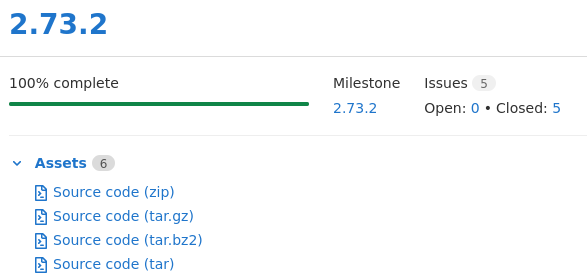
GitLab generates these assets automatically; releases are tied to the lifetime of a tag, and since we don’t allow tags to be deleted, releases cannot be deleted either. This would move archive management from download.gnome.org to gitlab.gnome.org—though we can likely set up redirects. For projects still using Autotools, it would mean saying goodbye to self-hosting release archives, but every project that has switched to Meson or CMake can already cope with it. As far as I know, GitLab source assets are not generated on the fly, and thus won’t change if the Git archive format changes, unlike with GitHub; but I’d have to double check.
Since releases can be created as part of the CI pipeline, we could automate that step as well, and tie it to a tag.
In short: there are alternatives to building our own tarballs. They depend on maintainers setting up a CI pipeline, which is another reason why maintainers that don’t have time or knowledge to do so, should ask for help, instead of waiting for the perfect time to learn how to do that. We have a large community, but we cannot go around asking people if they need help; please, be proactive.
I started writing templates for publishing API references; it needs some cleanup, and ideally it would be great if I could depend on the GNOME run time images instead of using a Fedora container. Still, if you either have non-bleeding edge dependencies, or you have your dependencies listed as Meson subprojects to fall back to, then you can already copy-paste the YAML into your project’s CI pipeline.
The GTK and libadwaita CI setup is a bit more complicated, as it allows publishing multiple references from different projects or branches, and it requires a per-project token which can only be generated by a maintainer.